March 12, 2026
Can you trust AI to tell you if you’re underpaid? I ran a structured experiment to find out, and the results should make you think twice before negotiating based on a chatbot’s number.
Headlines Up Front
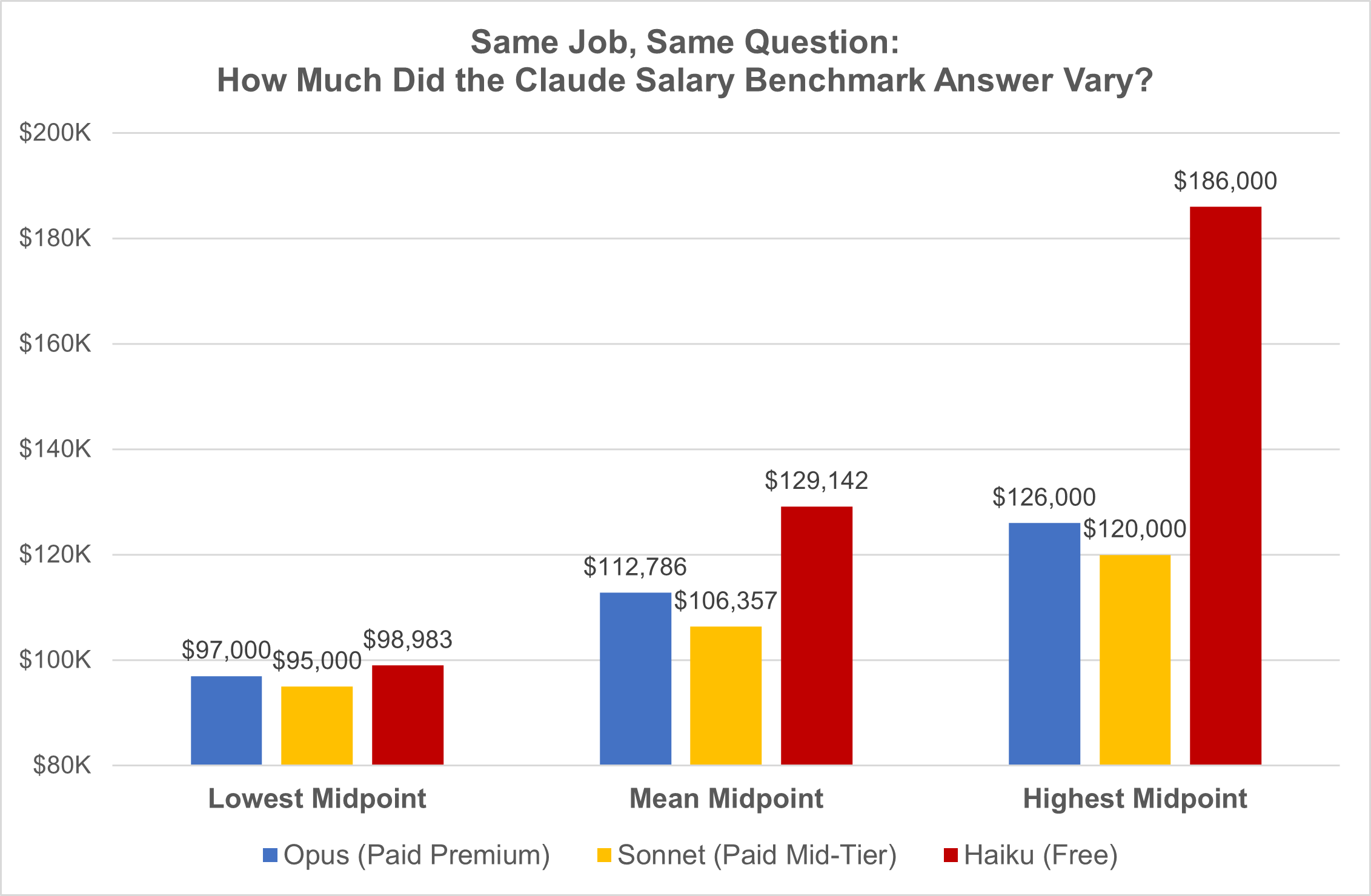
- The spread: Claude’s salary midpoint for the same job ranged from $95K to $186K across 42 queries. That’s a $91K gap.
- Free vs. paid: The free model (Haiku) had 2.5x more variability than the paid models. Its answers are essentially random.
- More detail isn’t always better: Moderately detailed prompts produced the tightest results. Pasting a full job description actually made things worse.
- Built-in randomness: The same prompt, same model, different day produced answers that varied by up to $61K.
- Best configuration: Sonnet 4.6 with org budget, role level, reporting line, and team size returned a perfectly reproducible $115K midpoint.
- The takeaway: AI is a conversation starter for salary research, not a source of truth. Use real compensation survey data for anything defensible.
The Experiment
I tested three versions of Anthropic’s Claude (Opus, the most powerful; Sonnet, mid-tier; and Haiku, the free model) on a single question: What is the market salary range for a Program Manager at a nonprofit in San Francisco?
I asked 42 times across 7 progressively detailed prompts and 2 separate sessions per model. Opus and Sonnet ran on my paid account; Haiku on a free burner account. Every session used a fresh incognito window to avoid memory. Same question. Same role. Just varying how much context I gave the AI.
The 7 prompts, in order of detail:
- Baseline: Just the role title and city, “What is the market midpoint and salary range for a Program Manager at a nonprofit in San Francisco?”
- + Org Budget: Added “$10 million annual operating budget”
- + Role Level & Reporting: Added “mid-level, reports to a Director”
- + Scope & Staff: Added “manages 3–5 direct reports, oversees a $1.5M program portfolio”
- + Sector Framing & Data Cue: Added “mission-driven nonprofit,” “nonprofit-specific compensation survey data,” and “San Francisco cost of labor”
- + Bilingual Requirement: Added “strongly preferred bilingual in Spanish or Cantonese”
- + Full Job Description: Pasted a complete, real JD
The question I wanted to answer: If a typical employee asks Claude “Am I being paid fairly,” how much should they trust the answer?
The Headline Number: How Wrong Could It Be?
Across all 42 responses, the salary midpoint ranged from $95,000 to $186,000. That’s a $91,000 spread for the exact same job.
If your actual market salary is $100,000:
- Haiku (free model): Midpoints from ~$99K to $186K, a potential error of -1% to +86%. That’s an $87K spread.
- Opus (premium paid model): ~$97K to $126K, an error range of -3% to +26%. A $29K spread.
- Sonnet (mid-tier paid model): ~$95K to $120K, an error range of -5% to +20%. The tightest spread at $25K.
- Best case (right model + right prompt): A ±5–20% range, or $5K to $20K of error.
Even in the best case, Claude’s salary estimate is a rough ballpark, not a number you should anchor a negotiation on. It tells whether the posted salary range for a role passes the “laugh test”, but not whether your current pay is market-competitive.
What Drives the Variability?
1. Which model you use matters. A lot.
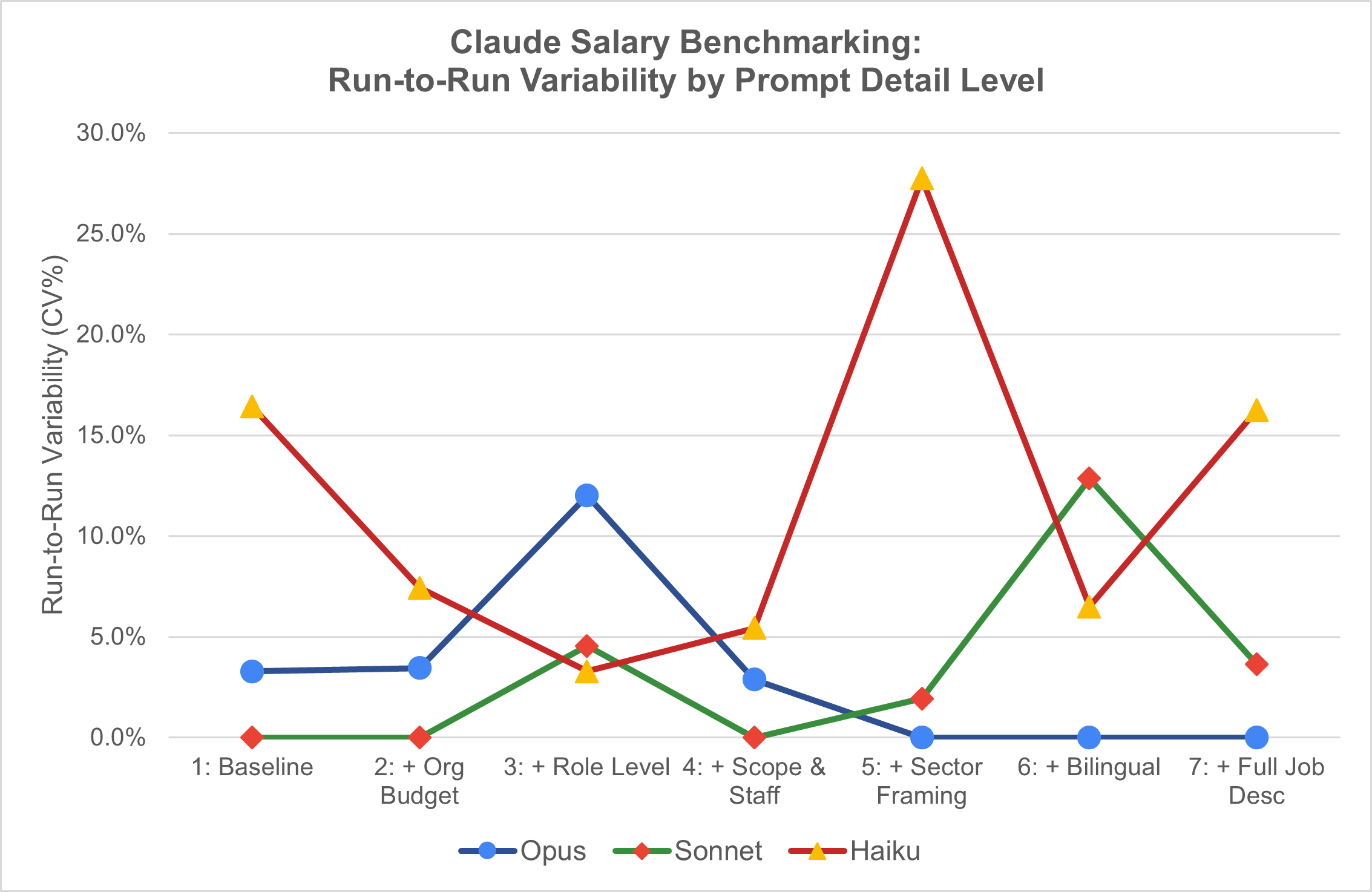
Sonnet 4.6 was the most reliable: just 7% CV (coefficient of variation, a measure of how spread out the results are) across all runs, with 3 out of 7 prompts returning identical midpoints across sessions. Opus was close at 8.9% CV with 3 perfect matches on different prompts.
Haiku was a different story: 18% CV, zero perfect matches, and a worst-case swing of $61,000 between sessions on the same prompt. If you’re using the free tier to check your salary, the number you get is essentially a coin flip.
2. Prompt detail has a Goldilocks zone
More context doesn’t mean better answers. The tightest cross-model agreement came from moderately detailed prompts (Runs 2 through 4: org budget, role level, team scope) with CVs of just 6.0–6.3%.
Adding sector-specific framing (Run 5) caused variability to jump to 22.6%, driven by Haiku returning $186K when the other models said $108K–$120K. And pasting a full job description (Run 7) made things worse, with CV jumping to 21.2%. More detail gave models more surface area to disagree on, not less.
The sweet spot? Include org budget, role level, reporting line, and team size. Stop there.
3. Ask the same question tomorrow, get a different answer
The most unsettling finding: identical prompts in separate incognito sessions produced different answers. Opus and Sonnet averaged a $5,000 shift (4–5%) between sessions, but swung up to $18K–$20K on their worst prompts. Haiku averaged a $23,000 shift, with a worst case of $61,000.
Even the perfect prompt has built-in randomness that no amount of engineering eliminates.
The Most Reliable Configuration I Found
Model: Sonnet 4.6 (paid, mid-tier)
Prompt level: Run 4, including org budget, role level, reporting line, team size, and portfolio scope
Result: $115,000 midpoint on both sessions, perfectly reproducible
Runner-up: Opus on sector framing and bilingual prompts (Runs 5–6) returned identical midpoints of $120K–$126K. The premium model stabilizes, but only with very specific sector context.
So Should You Use AI to Benchmark Your Salary?
AI is useful as a conversation starter, not a source of truth. If Claude says your midpoint is $115K and you’re making $85K, that’s a signal worth investigating. But it’s not evidence.
What AI can do well: give you a rough sanity check on order of magnitude, help you think through what factors affect your market value, and generate a starting framework for a compensation conversation.
What AI cannot do: replace actual compensation survey data (Radford, Mercer, Compdata, or nonprofit-specific sources like the FairPay Collaborative), give you a defensible number for a negotiation, or be consistent enough to compare across colleagues.
The Bottom Line
If your salary is $100,000, Claude’s best guess for your market rate could land anywhere from $95,000 to $186,000. Even with paid models and a well-crafted prompt, you’re looking at a ±5–20% margin of error.
That’s not “wrong” in the way a broken calculator is wrong. It’s unreliable in the way a friend who “has read the Wikipedia article” is unreliable. Useful for orienting yourself. Dangerous if you treat it as ground truth.
Methodology: 42 total observations (7 prompt levels × 3 Claude models × 2 independent sessions). Each session used a fresh incognito browser window. Opus and Sonnet tested via paid Claude Max subscription; Haiku via free account. All prompts asked for fixed Range Min, Midpoint, and Range Max values. Analysis focused on midpoint as the primary reliability metric.
March 2, 2026
Question: Can LLMs produce market benchmarks that are reliable enough to inform real compensation decisions (and if so, where does it break down)? Put another way: has AI gotten "good enough" to replace compiled surveys or comp databases?
TL;DR In a pilot test using 15 common nonprofit roles scoped to San Francisco nonprofits (25–50 FTE), LLM-generated market medians tracked “paper survey” benchmarks closely (high agreement on role ordering and relative differentials), but diverged more from leading national compensation databases, especially for executive roles. In other words, LLMs do a good job ranking pay rates between jobs but are probably less accurate at giving you a true “range” in the absence of other org context. My recommendation: use LLMs for quick triangulation (“do Controller or Sr. Director of Finance typically pay more at Oakland nonprofits?”), job-matching sanity checks, and early range development. Do not use them as a single source of truth for pricing decisions, and always calibrate with at least one traditional benchmark source, especially above the director level.
Context
If you’re a CPO or HR leader, you already know the pain points of market benchmarking:
- Comp databases or surveys are expensive and often sold in bundles
- Job matching takes time and still produces “depends who you ask” answers
- Scope and leveling differences can swamp the number you hoped would be definitive
- You need something fast enough to support real decisions, but defensible enough to stand up in leadership and comp committee conversations
At the same time, large language models (LLMs) can produce salary benchmarks in seconds. That’s both enticing and risky. The real question isn’t “can an LLM give you a number?” It’s “how accurate are those numbers compared to traditional sources?”
To explore this, I ran a small pilot comparing LLM-produced market medians to two categories of traditional benchmarking sources:
- Survey-style benchmarks (compiled survey outputs): I pulled two leading national or regional surveys typically used by Bay Area nonprofits
- Database-style benchmarks (leading national comp databases): I pulled from three widely used national compensation databases
I then ran three LLMs (ChatGPT, Claude, and Gemini) with a consistent market scope: San Francisco/Bay Area, nonprofits, 25–50 FTE, P50/median pay as the anchor point.
See the Appendix below for an example of the data gathered for a “Development Manager” role.
A quick note on language: for the purposes of this analysis, “accuracy” means “agreement with traditional sources under a comparable set of market parameters.” In compensation benchmarking, there is rarely a single “true” number; there are multiple legitimate answers depending on how the cut is defined and how the job is matched.
Method in Plain English
For each role, I created “consensus” estimates to reduce single-source noise:
- LLM consensus: average of the three LLM medians
- Survey consensus: median of the “paper survey” medians
- Database consensus: median of the database-style medians
Then I compared the consensus estimates as scatter plots (one dot per role). I used R² as a quick measure of agreement, a 45-degree line (perfect agreement) to show level differences, a fitted regression line to show systematic bias, and outlier labeling to identify which roles drove divergence.
This is deliberately not a “gotcha” test, but a practical question: if you’re benchmarking in the real world, does the LLM output behave like market data you already recognize?
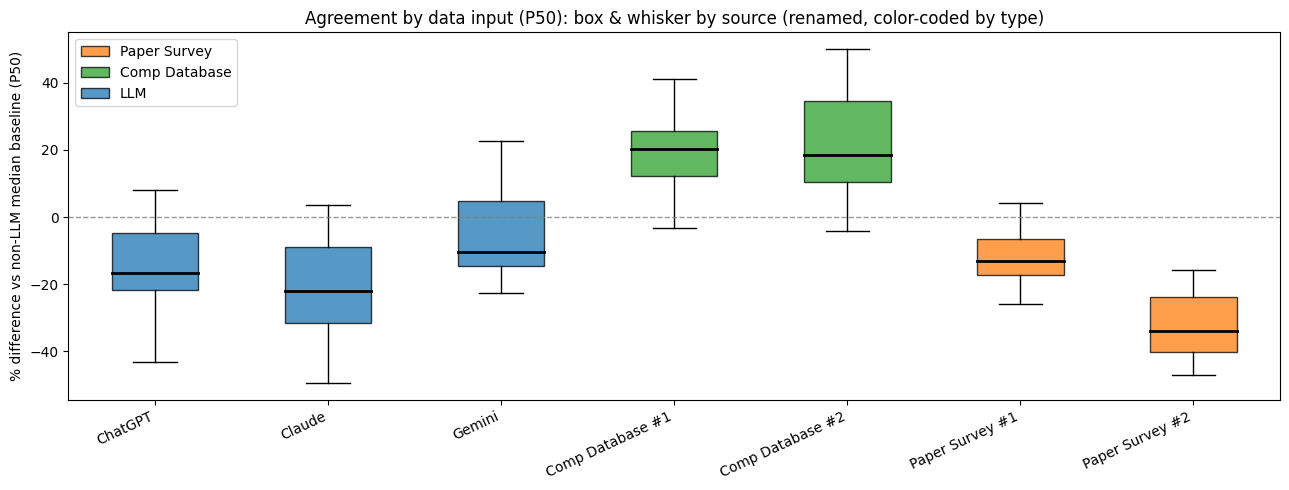
Results: What the Data Showed
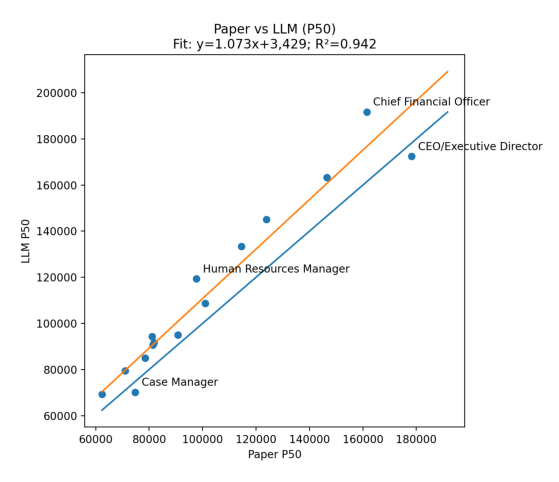
1. Paper surveys vs. LLMs: strongest agreement — R² = 0.94. Across roles, LLMs tracked survey-style medians closely. If a role priced higher in surveys, it tended to price higher in LLM outputs too.
2. Paper surveys vs. database-style benchmarks: solid agreement, more spread — R² = 0.88. Even traditional sources diverged meaningfully, especially as roles moved up-market in scope. This is a useful reminder that benchmarking tools are not interchangeable without careful cut alignment.
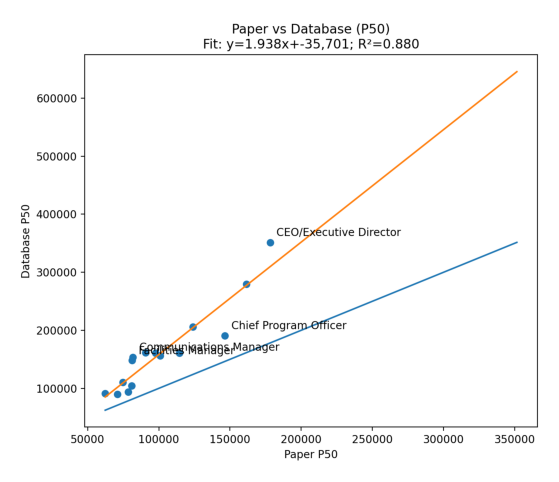
3. Database-style benchmarks vs. LLMs: weakest agreement — R² ≈ 0.77. LLMs did not reproduce database-style patterns as reliably, particularly at the senior end.
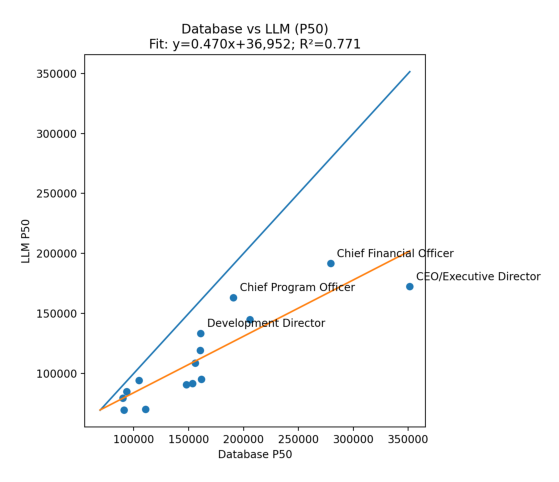
Where disagreement clustered: The biggest divergence showed up in executive and top-of-house roles (CEO/ED and CFO equivalents). Mid-level manager and professional roles were more stable across sources.
What that pattern usually means in practice: Executive roles have the highest variance in real life because scope is typically more ambiguous, incentives and total cash conventions vary, and organization-size elasticity is larger. Traditional databases often encode leveling and job architecture conventions in ways that LLM prompting does not consistently capture unless scope is specified very tightly. For example: you will benchmark a “VP of Finance” differently depending on whether the organization also has a CFO.
Interpretation: What This (Might) Mean for LLM Accuracy
The headline takeaway is not “AI is/is not ready to replace comp databases.” The takeaway is: LLMs can be directionally reliable for benchmarking common roles when scoped well, but they are more fragile than traditional sources when scope and leveling complexity increase.
LLMs appear strong on relative pricing. Across roles, LLM outputs tracked the “shape” of the market well against survey-style benchmarks. That’s useful because many real decisions rely on relative relationships — questions like:
- Are we preserving reasonable internal differentials?
- Does a draft range architecture look broadly aligned with market trends?
- Should we post a higher or lower range for a new role compared to an existing one?
LLMs appear weaker on database-style “cut fidelity.” Databases behave differently from survey-style sources because they embed specific job-leveling conventions, location factors, sector, org-size, and embedded job-matching logic. LLMs can approximate that, but ultimately they are a “black box” in the same way that comp databases can be — with even less insight into the methodology for how that particular number or range was created.
Executive roles are the “your mileage will vary” zone. If you’re a seasoned comp pro, the data in this little pilot study behaved as you might expect: the higher the scope ambiguity, the more sources diverged. If you’re setting executive pay, the cost of being wrong is large and the defensibility bar is high. LLMs can help you develop a directional hypothesis about pay rates, but not final decisions. I might use an LLM to get a general sense for “Nonprofit CEO pay in Louisville for orgs around $10M,” but wouldn’t use it for structure design or individual pay decisions.
Recommendations for HR Leaders and Consultants
Consider using LLMs for:
- Quick triangulation when you’re early in a project
- Role definition and job-matching sanity checks, especially when titles are misleading (“this role is titled Director but JD reads more like a Manager”)
- Drafting a first-pass range hypothesis for common roles, to be validated
- Identifying where scope questions matter most — if an LLM “range estimate” swings a lot when you change a particular variable, it is probably flagging a scoping problem
Do not use LLMs as a single source of truth for:
- Executive compensation ranges or placement decisions
- Any situation where you need to defend the benchmark to a board or comp committee
- Roles with high scope variability (CFO/Controller, COO, heads of development, heads of product/program) unless you have a tight scope spec and at least one traditional anchor point
How to make LLM benchmarking meaningfully safer:
- Lock the market definition in writing (geo, sector, org size, pay basis) and reuse it verbatim
- Run multiple models, not one (e.g., ChatGPT and Claude); look for convergence rather than a single answer
- Use the paid version of these tools (free versions are much less reliable)
- Calibrate: anchor to one trusted benchmark point from a traditional source, then use LLMs if you need to fill gaps
- Treat LLM outputs as hypotheses; test by adjusting one variable at a time to see what’s driving the number
- Keep an audit trail: prompts used, the assumptions you gave the model, and the outputs along the way
- Make sure you’ve turned off the “use my data for training” option in whichever model you use
Closing Thought
LLMs are already useful in benchmarking workflows; the mistake is treating them as a replacement for market data. In my “little pilot,” they performed surprisingly well against paper survey benchmarks under a defined market cut, and less well against database-style outputs. Unsurprisingly, the gaps were biggest with executive positions — where identifying the “right” pay rates are hardest anyway.
If you approach LLMs as a speed tool for triangulation and scoping, they might add real value. If you treat them as the final answer, you will eventually get burned — most likely at the executive level or in roles where scope is ambiguous.
If you’re thinking through how to integrate LLMs into your benchmarking workflow in a way that’s practical and defensible, I’m happy to compare notes; this is an area I’m actively developing thinking on. ben@thrulinecomp.com
Appendix: Sample Role Comparison — Development Manager
Market Parameters: San Francisco/Bay Area, Nonprofits, 25–50 FTE
| Source Type |
Source (masked) |
Market Scope Used |
P50 (median) |
Notes |
| LLM |
ChatGPT |
San Francisco; Nonprofit; 25–50 FTE |
$95,000 |
Prompted to target scope |
| LLM |
Claude |
San Francisco; Nonprofit; 25–50 FTE |
$88,000 |
Prompted to target scope |
| LLM |
Gemini |
San Francisco; Nonprofit; 25–50 FTE |
$102,000 |
Prompted to target scope |
| Survey-style |
Survey A (national nonprofit survey) |
Closest available cut |
$101,503 |
Masked source name |
| Survey-style |
Survey B (regional nonprofit survey) |
Closest available cut |
$80,000 |
Masked source name |
| Database-style |
Comp database 1 (leading national platform) |
San Francisco / org-size cut |
$141,100 |
Masked source name |
| Database-style |
Comp database 2 (leading national platform) |
San Francisco / org-size cut |
$181,971 |
Masked source name |
| Consensus |
LLM average |
N/A |
$95,000 |
Average of 3 LLM medians |
| Consensus |
Survey median |
N/A |
$90,752 |
Median of 2 survey-style medians |
| Consensus |
Database median |
N/A |
$161,536 |
Median of 2 database medians |
| Spread |
Range across all sources |
N/A |
$101,971 |
Max minus min across all sources |
February 25, 2026
I'm excited to launch this blog as a space to share insights, research, and practical guidance on compensation design for mission-driven organizations.
Over the coming months, I'll be writing about topics like:
- How to conduct a meaningful pay equity analysis
- Building compensation philosophies that reflect your values
- Navigating market benchmarking for nonprofit roles
- Communicating pay decisions with transparency and trust
Stay tuned for more, and feel free to reach out if there's a topic you'd like me to cover.